Preparing a Data Holder for Clinical Research
The Data Space Platform transforms a Data Holder’s latent clinical data into a valuable, research-ready asset. This process, called Data Enablement, enhances a hospital’s ability to participate in multicenter research, improve operations, and generate new revenue streams while maintaining full control over its data. By standardizing its data, an institution can attract cutting-edge research, offer its clinicians opportunities for co-authorship on publications, and ultimately support better clinical decision-making at home.

The enablement process is divided into three main phases:
- Dimensioning: Analysis and need understanding.
- Deployment: Go-to architecture for hospital organizations.
- Readiness: Ensuring data holders are prepared for research.
1. Dimensioning: A Formal Feasibility Assessment
Think of the Dimensioning phase as a comprehensive feasibility study, similar to a site selection and qualification process in a clinical trial. The goal is to deeply understand the hospital’s data landscape to de-risk the project and ensure a successful outcome. This is a collaborative process involving workshops and interviews with the hospital’s IT staff, data managers, and clinical department heads.
The entire process is documented in a key deliverable: the Data Landscape & Feasibility Report. This report provides a complete inventory of the hospital’s data assets and a clear plan for the subsequent deployment.
The assessment focuses on three key areas:
Data Sources & Content
First, we inventory all clinical systems that hold patient data. This goes beyond just listing the systems; we analyze their content, structure, and accessibility.
- System Identification: We identify all relevant systems, such as:
- Electronic Health Records (EHRs): The digital version of a patient’s paper chart, containing their complete medical history from one provider.
- Laboratory Information Systems (LIS): Systems that manage and store data from a hospital’s laboratory tests.
- Radiology Information Systems (RIS): Systems used to manage and store imaging data and associated reports.
- Prescription systems: Systems that manage medication orders and administration records.
- Data Profiling: We analyze the content and format of these sources, which can range from relational databases to flat files, HL7, or FHIR. We assess the completeness of key data points (e.g., what percentage of lab results have valid units?) and the volume of data available over time.
Data Terminology and Unstructured Data
A critical part of the assessment is understanding how clinical information is coded and captured.
- Terminology Analysis: We analyze the coding systems used for structured data. We determine if the hospital uses international standards like SNOMED CT, LOINC, or ICD-10, or if it relies on internal, local codes. If non-standard codes are used, we assess the availability of local data dictionaries to inform the mapping strategy.
- Unstructured Data Assessment: We review the format and content of unstructured sources, like clinical notes or discharge summaries, to determine their suitability for NLP extraction.
Example: We identify that Hospital X uses a local, non-standard coding system for diagnoses in its EHR. We document the structure of this system and confirm the existence of a data dictionary. We also analyze the format of their clinical notes and confirm they are available as plain text, making them ideal for NLP.
Data Infrastructure & Governance
Finally, we assess the technical and administrative environment.
- Infrastructure Review: We analyze the location and governance of the hospital’s data sources, whether they are on-premise, in the cloud, or on a third-party location. This helps us design the optimal deployment architecture.
- Governance and Privacy: We review the hospital’s existing data governance policies, privacy protocols, and the process for obtaining ethical approvals (e.g., IRB/EC) for research.
2. Deployment and Core Processes
Once we have a clear understanding of the hospital’s data landscape, we deploy our platform and begin the core data processing. Our architecture is adaptable to the specific requirements of each hospital, but the fundamental processes of extraction, transformation, and loading (ETL) remain the same.
ELT Process: From Raw Data to OMOP CDM
The ELT (Extract, Load, Transform) process transforms raw data from various hospital systems into the standardized OMOP Common Data Model. We use an ELT approach where raw data is first loaded into a secure staging area within the hospital’s environment. This allows for a clear audit trail and ensures that all transformations are performed on a centralized, controlled copy of the data before it is loaded into the final OMOP CDM structure.
- Extraction: We extract data from the identified sources, including both structured data (e.g., lab results, diagnosis codes) and unstructured data (e.g., clinical notes).
- Load: The raw data is loaded into the Data Space environment within the hospital’s secure infrastructure.
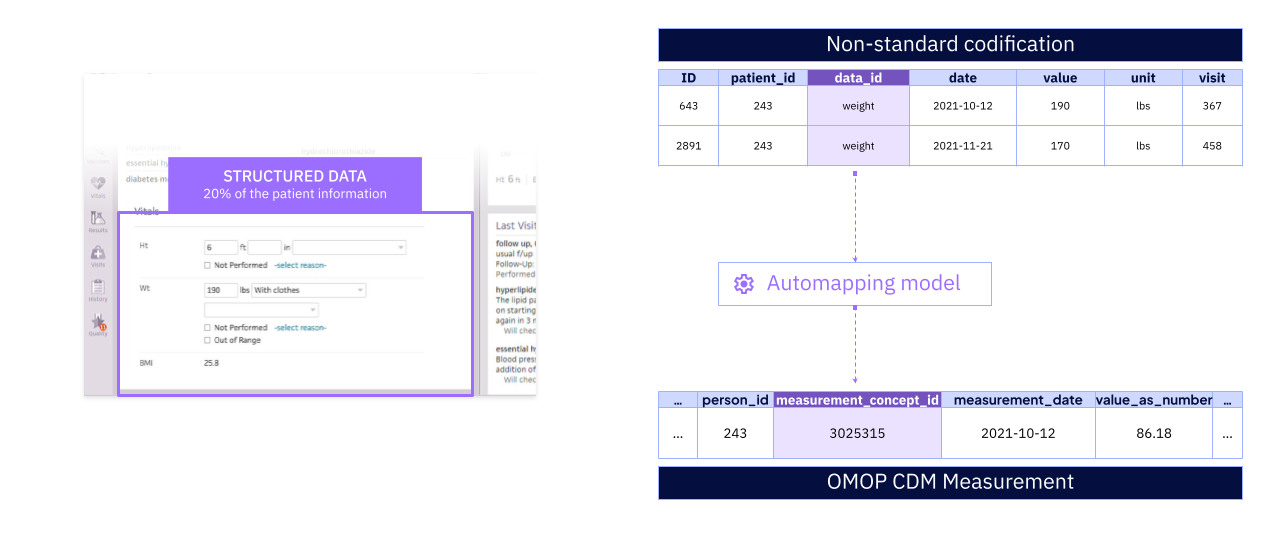
- Transformation: Once loaded, the transformation process begins. This is the most critical step, where we clean, standardize, and harmonize the data. This includes two key AI-driven processes, each designed for full transparency and validation:
- Automated Terminology Mapping (ATM): For structured data, our AI models map different coding systems—whether international standards or internal hospital codes—to a single, standard OMOP vocabulary. The performance of these models is rigorously validated, and any mappings that fall below a pre-defined confidence threshold are flagged for manual review by clinical terminologists. All mapping decisions are logged in a detailed audit trail. Example: The ATM model maps 98% of Hospital X’s local diagnosis codes to standard OMOP concepts. The remaining 2% are reviewed and mapped manually.
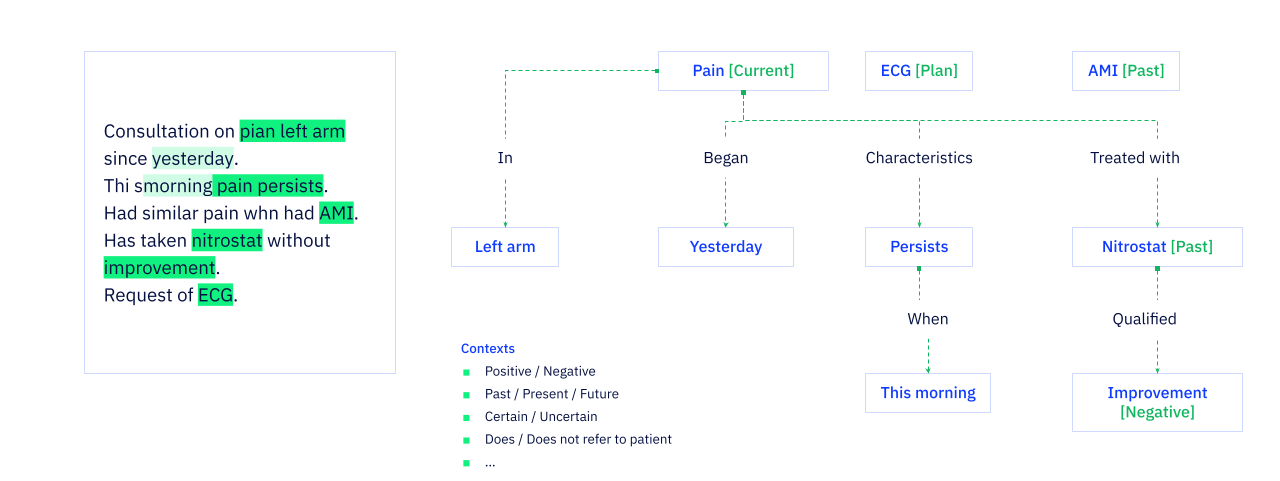
- Natural Language Processing (NLP): For unstructured text, our NLP models extract clinically relevant information. The models identify medical concepts (like diagnoses, medications, and symptoms), understand their context (e.g., negation, family history, current vs. past conditions), and map them to the appropriate OMOP concepts. These models are benchmarked against manually annotated text, and their accuracy is documented. The process allows for human-in-the-loop review to ensure the highest quality of extracted data. Example: The NLP model processes clinical notes to identify diabetic patients with a history of hypertension, information that was not available in the structured data.
- Automated Terminology Mapping (ATM): For structured data, our AI models map different coding systems—whether international standards or internal hospital codes—to a single, standard OMOP vocabulary. The performance of these models is rigorously validated, and any mappings that fall below a pre-defined confidence threshold are flagged for manual review by clinical terminologists. All mapping decisions are logged in a detailed audit trail. Example: The ATM model maps 98% of Hospital X’s local diagnosis codes to standard OMOP concepts. The remaining 2% are reviewed and mapped manually.
A Practical Introduction to our AI Tools
For those unfamiliar with AI, it’s helpful to think of these tools as highly advanced assistants that perform specific, repetitive tasks at a massive scale.
-
What is Automated Terminology Mapping (ATM)?
Think of ATM as an automated and highly accurate version of a WHODrug or MedDRA dictionary coder. In a clinical trial, a data manager might manually map a reported term like “sore throat” to the official MedDRA term “Pharyngitis.” Our ATM does the same thing, but for millions of records at once. It takes a hospital’s local, non-standard codes (e.g., an internal code
1234for “Type 2 Diabetes”) and correctly maps them to the single, globally recognized OMOP standard concept for that condition. -
What is Natural Language Processing (NLP)?
Think of NLP as a team of expert Clinical Research Associates (CRAs) who can read through thousands of pages of source documents (like doctor’s notes) in seconds. A CRA might read a note that says “Patient reports no history of heart attack” and record “Myocardial Infarction: No” in the eCRF. Our NLP models do precisely this. They read unstructured text, identify the key clinical concepts (like “heart attack”), understand the context (the patient does not have this condition), and then structure that information correctly in the OMOP CDM. This allows us to extract critical information that would otherwise be locked away in free text.
Anonymization
Throughout the ETL process, we apply a robust, two-step anonymization process to protect patient privacy:
- Identifier Removal: We detect and hash personal identifier fields, such as names and ID numbers, and then remove or replace them.
- Text Anonymization: We use a combination of pattern matching and probabilistic models to identify and remove personal data from unstructured text, such as clinical notes.

3. Readiness: Finalizing the Research Environment
Once the deployment and data processing pipelines are in place, we work with the hospital to finalize the environment for data mediation. This involves ensuring readiness across four key areas:
Technical Readiness
- Finalizing the OMOP Data Warehouse: Data from all hospital sources is activated and normalized to the OMOP Common Data Model, creating a single, queryable source of truth for research.
AI Readiness
- Enriching the Data with AI-Powered Insights: The validated Automated Terminology Mapping (ATM) and Natural Language Processing (NLP) pipelines are operational, continuously enriching both structured and unstructured data as it enters the system.
Governance and Mediation Readiness
- Establishing a Data Governance Framework: We help establish a clear governance framework, often through a joint steering committee, to define data ownership, usage rights, and the formal approval process for all research requests.
- Defining the Hospital Approval Workflow: A clear, documented workflow is established for the hospital to review and approve research projects, ensuring alignment with institutional priorities and ethical guidelines.
- Facilitating Industry Engagement: We facilitate engagement with industry stakeholders for multicenter research projects.
- Streamlining Contract Management: We help manage the contractual agreements for data use, simplifying the administrative burden on the hospital.
Compliance Readiness
- Executing a Master Services Agreement (MSA): An MSA is established to govern the deployment and ongoing use of the data platform.
- Ensuring Regulatory Compliance: We ensure that data is fully anonymized for data users and pseudonymized for data holders, in full compliance with regulations like GDPR.