A Guide to Real-World Data Analysis
Context
Clinical data generated during routine patient care is a primary source of real-world evidence. However, its direct use in research is impeded by three fundamental, widely recognized challenges:
- Lack of Standardization: Clinical data is captured in diverse, unstructured formats across different healthcare systems. This heterogeneity makes it impossible to aggregate and analyze the data at scale. A single condition, for instance, may be recorded using dozens of non-standard local terms.
- Patient Privacy Requirements: Health records contain sensitive personal information protected by stringent regulations like GDPR. Any use for research requires the removal of all identifiers—a complex and specialized process.
- Operational Barriers: Preparing data for research demands significant technical expertise, time, and resources, which are often beyond the scope of individual healthcare or research institutions.
Our Approach
IOMED provides the infrastructure and processes to bridge this gap, converting raw clinical data into a standardized, privacy-compliant resource for scientific investigation.
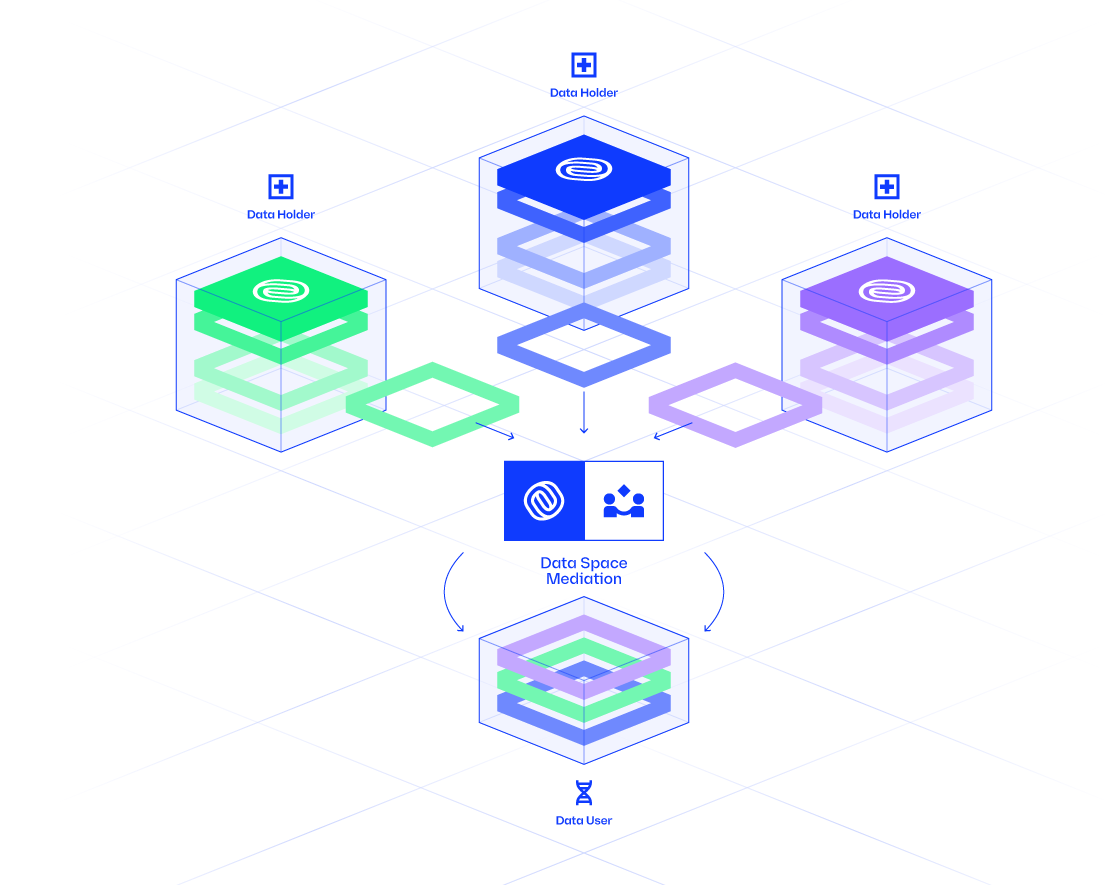
For Healthcare Institutions (Data Holders)
Our platform provides hospitals and other data custodians with the tools to prepare their data for research while ensuring it never leaves their secure environment. We enable institutions to:
- Standardize Clinical Data: We process and map disparate data from electronic health records to the OMOP Common Data Model (CDM). Much like CDISC SDTM provides a standard structure for clinical trial data, the OMOP CDM is the global standard for observational research, organizing information into key tables such as
PERSON,CONDITION_OCCURRENCE(diagnoses), andDRUG_EXPOSURE(medications). This creates a uniform structure for consistent analysis. This mapping is powered by a validated pipeline that includes advanced techniques like Natural Language Processing (NLP) and Automated Terminology Mapping (ATM) to enhance the completeness of extracted information, with all steps subject to rigorous quality control. - Protect Patient Privacy: Our system applies robust anonymization techniques to remove all personally identifiable information. This process ensures the resulting dataset complies with data protection regulations.
- Maintain Control and Compliance: The entire data preparation process is auditable and governed by clear protocols, giving institutions full oversight and ensuring regulatory adherence.
For Research Organizations (Data Users)
We provide researchers with a streamlined and compliant method to access the specific data required for their work. Our platform allows them to:
- Define and Request Datasets: Using tools like Atlas (a graphical user interface) or R packages, researchers can construct precise queries to define patient cohorts and specify the exact variables needed for their study. This allows them to request a dataset tailored to their specific research question.
- Access Research-Ready Data: We deliver fully anonymized, standardized, and quality-checked datasets. This allows research teams to proceed directly to analysis, confident that the data is reliable and has been sourced ethically and legally.
- Ensure Data Integrity: We implement a multi-layered Quality Assurance framework with automated checks and expert validation to verify the accuracy, completeness, and plausibility of the data.
The Data Mediation Process
Data Mediation is the structured process of transforming raw clinical data into a standardized, research-ready resource. This approach ensures data integrity, regulatory compliance, and scientific rigor. The process begins with data preparation, where partnerships with data holders are established, ethical approvals are secured, and disparate data sources are integrated into a uniform format.
Following preparation, the core of the Data Mediation is executed. This involves defining research objectives, identifying patient cohorts, specifying the data of interest, and verifying data quality. This ensures that the final dataset is tailored to the specific research question and meets the highest standards of quality and reliability. You can find a more detailed explanation in our Data Mediation documentation.

The key stages of this process include:
-
Study Definition: Researchers initiate a study by developing a protocol, defining the required clinical variables through concept sets (which are analogous to code lists or MedDRA queries in a clinical trial), and specifying the patient population (cohort). This ensures the study is scientifically valid and provides data holders with full transparency.
-
Institutional Approval: Data holders review the request, secure necessary approvals from ethics committees, and finalize contractual agreements before granting access to the data.
-
Quality Assurance: We perform rigorous checks to validate the data against the original request. This process is similar to a Data Validation Plan in a clinical study and includes automated verification and validation by clinical experts to ensure the dataset is accurate, complete, and clinically plausible.
-
Compliance and Delivery: After a final compliance check, the fully anonymized and standardized dataset is securely delivered to the researcher.
Health Data Analysis
The Health Data Analysis phase is where the research-ready datasets are used for scientific investigation. This process is governed by rigorous protocols to ensure data quality, patient privacy, and regulatory compliance. You can find a more detailed explanation in our Data Analysis documentation.
- Flexible Analysis Options: We support two primary models for data analysis. Researchers can receive the final, anonymized dataset for analysis in their own environment, or for maximum security, the analysis can be executed within the data holder’s infrastructure using tools like the OHDSI R packages or Atlas. In the latter model, only aggregated results are returned to the researcher.
This documentation serves as a comprehensive educational site for the Data Analysis process using the OHDSI toolkit. It includes a detailed introduction and tutorials for the R package ecosystem, designed to help you execute real-world evidence studies using the OMOP Common Data Model (CDM).
Understanding the OHDSI Ecosystem
For professionals accustomed to the structured environment of clinical trials, the world of real-world data can seem ambiguous. The Observational Health Data Sciences and Informatics (OHDSI)1 network provides the standards and tools to bring rigor and reproducibility to this domain.
A simple way to frame these concepts is through an analogy: OHDSI is to the OMOP Common Data Model as the CDISC consortium is to SDTM.
-
OHDSI & CDISC (The Organizations): Just as CDISC is a global, multi-stakeholder collaborative that develops standards for clinical trials, OHDSI (pronounced “Odyssey”) is the equivalent for observational research. It develops the open-source standards and tools needed for large-scale analysis of real-world health data.
-
OMOP CDM & SDTM (The Data Standards): Just as SDTM provides a standardized structure for submitting clinical trial data to regulatory authorities, the OMOP Common Data Model (CDM) provides a standardized structure for observational data. It organizes diverse clinical datasets (from electronic health records, claims, etc.) into a consistent format with a common terminology. This allows researchers to run the same analysis code across different datasets from around the world, confident that the underlying data structure is the same.
By converting raw data to the OMOP CDM, we create a research-ready asset that is not only standardized but also part of a global ecosystem of tools and expertise.